Artificial Intelligence (AI) dan Machine Learning (ML) telah menjadi bagian tak terpisahkan dari kehidupan kita sehari-hari. Dari rekomendasi film di Netflix hingga mobil swakemudi, AI dan ML mengubah cara kita berinteraksi dengan teknologi. Tapi, pernahkah Anda bertanya-tanya, bagaimana sebenarnya cara kerja AI dan Machine Learning? Artikel ini akan membahasnya secara mendalam, dari algoritma dasar hingga model pembelajaran yang canggih. Mari kita selami dunia AI dan ML!
1. Pengantar: Apa Itu AI, Machine Learning, dan Deep Learning?
Sebelum kita membahas cara kerja AI dan Machine Learning secara detail, penting untuk memahami perbedaan antara ketiga istilah ini:
-
Artificial Intelligence (AI): Konsep yang luas, AI adalah kemampuan mesin untuk meniru kecerdasan manusia. Ini mencakup berbagai teknik, dari aturan sederhana hingga algoritma yang kompleks. Tujuan AI adalah menciptakan sistem yang dapat berpikir, belajar, dan memecahkan masalah layaknya manusia.
-
Machine Learning (ML): Subset dari AI, ML adalah kemampuan mesin untuk belajar dari data tanpa diprogram secara eksplisit. Alih-alih diberikan instruksi yang rinci, mesin ML belajar pola dan membuat prediksi berdasarkan data yang diberikan.
-
Deep Learning (DL): Subset dari ML, DL menggunakan jaringan saraf tiruan dengan banyak lapisan (deep neural networks) untuk menganalisis data yang kompleks. DL sangat efektif dalam mengenali pola rumit seperti gambar, suara, dan teks.
Dengan kata lain, AI adalah payungnya, ML adalah salah satu cabangnya, dan DL adalah cabang yang lebih spesifik dari ML.
2. Fondasi: Data Adalah Kunci Keberhasilan Machine Learning
Cara kerja AI dan Machine Learning sangat bergantung pada data. Data adalah bahan bakar yang menggerakkan algoritma dan model pembelajaran. Semakin banyak data berkualitas yang diberikan, semakin baik model ML dapat belajar dan membuat prediksi yang akurat.
Proses pengumpulan dan persiapan data sangat krusial. Data harus relevan, bersih (bebas dari kesalahan dan inkonsistensi), dan terstruktur dengan baik. Proses ini sering disebut data preprocessing dan memakan sebagian besar waktu dalam proyek ML. Data preprocessing meliputi:
- Pembersihan Data (Data Cleaning): Menghapus atau memperbaiki data yang hilang, duplikat, atau tidak akurat.
- Transformasi Data (Data Transformation): Mengubah data ke format yang sesuai untuk algoritma ML. Contohnya, mengubah data teks menjadi angka.
- Normalisasi Data (Data Normalization): Menyesuaikan skala data agar memiliki rentang nilai yang sama, mencegah algoritma bias terhadap fitur dengan nilai yang lebih besar.
- Reduksi Dimensi (Dimensionality Reduction): Mengurangi jumlah fitur yang digunakan dalam model, mempercepat proses pembelajaran dan mencegah overfitting (model terlalu kompleks dan hanya bagus pada data pelatihan).
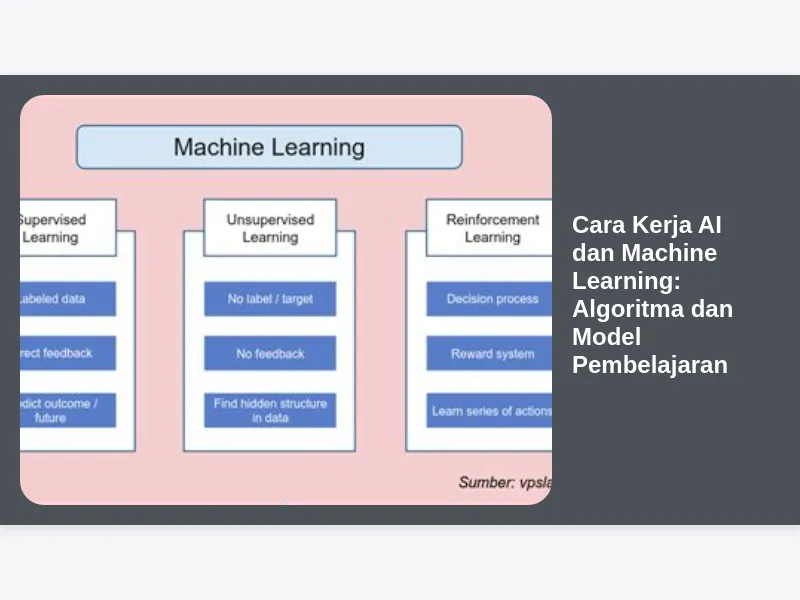
3. Algoritma Machine Learning: Memahami Berbagai Jenis Pembelajaran
Setelah data disiapkan, langkah selanjutnya adalah memilih algoritma ML yang tepat. Ada berbagai jenis algoritma ML, masing-masing dengan kelebihan dan kekurangannya. Pemilihan algoritma tergantung pada jenis masalah yang ingin dipecahkan dan karakteristik data yang tersedia. Secara umum, algoritma ML dapat dikelompokkan menjadi:
-
Supervised Learning (Pembelajaran Terawasi): Model dilatih menggunakan data yang sudah berlabel (labeled data). Artinya, setiap data masukan memiliki jawaban yang benar (target variable). Tujuan supervised learning adalah mempelajari hubungan antara masukan dan keluaran sehingga model dapat memprediksi keluaran untuk data masukan baru. Contoh algoritma:
- Regresi Linear (Linear Regression): Memprediksi nilai numerik berdasarkan hubungan linear antara variabel independen dan dependen.
- Regresi Logistik (Logistic Regression): Memprediksi probabilitas suatu peristiwa terjadi (misalnya, apakah seorang pelanggan akan membeli produk atau tidak).
- Support Vector Machines (SVM): Mencari hyperplane yang optimal untuk memisahkan data ke dalam kelas-kelas yang berbeda.
- Decision Trees (Pohon Keputusan): Membuat serangkaian aturan untuk mengklasifikasikan data berdasarkan fitur-fitur yang relevan.
- Random Forest (Hutan Acak): Ensemble dari banyak decision trees, meningkatkan akurasi dan robustness model.
- K-Nearest Neighbors (KNN): Mengklasifikasikan data berdasarkan mayoritas kelas dari k tetangga terdekatnya.
-
Unsupervised Learning (Pembelajaran Tidak Terawasi): Model dilatih menggunakan data yang tidak berlabel (unlabeled data). Tujuan unsupervised learning adalah menemukan pola dan struktur tersembunyi dalam data. Contoh algoritma:
- K-Means Clustering: Mengelompokkan data ke dalam k kelompok berdasarkan kesamaan fitur.
- Hierarchical Clustering: Membangun hierarki kelompok data, memungkinkan untuk menganalisis hubungan antar kelompok.
- Principal Component Analysis (PCA): Mengurangi dimensi data dengan mengidentifikasi komponen utama yang menjelaskan variasi terbesar dalam data.
- Anomaly Detection (Deteksi Anomali): Mengidentifikasi data yang tidak biasa atau berbeda dari pola normal.
-
Reinforcement Learning (Pembelajaran Penguatan): Model belajar dengan berinteraksi dengan lingkungan dan menerima umpan balik (reward atau punishment) atas tindakannya. Tujuan reinforcement learning adalah mengembangkan strategi (policy) yang memaksimalkan reward yang diterima dari lingkungan. Contoh aplikasi:
- Game AI (misalnya, AlphaGo): Melatih agen untuk bermain game dengan tingkat keahlian manusia atau bahkan lebih tinggi.
- Robotika: Melatih robot untuk melakukan tugas-tugas kompleks di dunia nyata.
- Sistem Rekomendasi: Mengoptimalkan rekomendasi produk atau konten berdasarkan interaksi pengguna.
4. Model Pembelajaran: Dari Training hingga Evaluasi
Setelah memilih algoritma yang tepat, langkah selanjutnya adalah melatih model ML. Cara kerja AI dan Machine Learning dalam pelatihan model adalah dengan memberikan data pelatihan kepada algoritma. Algoritma kemudian belajar dari data tersebut dan menyesuaikan parameter-parameter internalnya untuk meminimalkan kesalahan prediksi.
Proses pelatihan model ML biasanya melibatkan langkah-langkah berikut:
- Split Data: Membagi data menjadi dua bagian: data pelatihan (training data) dan data pengujian (testing data). Data pelatihan digunakan untuk melatih model, sedangkan data pengujian digunakan untuk mengevaluasi kinerja model setelah dilatih. Seringkali ditambahkan juga data validasi (validation data) yang digunakan untuk fine-tuning hyperparameter model.
- Training Model: Memberikan data pelatihan kepada algoritma dan membiarkannya belajar pola dan hubungan dalam data. Proses ini melibatkan iterasi berulang-ulang di mana algoritma menyesuaikan parameternya untuk meminimalkan kesalahan prediksi.
- Evaluasi Model: Menggunakan data pengujian untuk mengevaluasi kinerja model. Metrik evaluasi yang digunakan tergantung pada jenis masalah yang dipecahkan. Misalnya, untuk masalah klasifikasi, metrik yang umum digunakan adalah akurasi, presisi, recall, dan F1-score. Untuk masalah regresi, metrik yang umum digunakan adalah Mean Squared Error (MSE) dan R-squared.
- Fine-tuning Model: Jika kinerja model tidak memuaskan, parameter-parameter model dapat disesuaikan (fine-tuned) untuk meningkatkan akurasi. Proses ini sering melibatkan eksperimen dengan berbagai kombinasi parameter dan menggunakan data validasi untuk memilih kombinasi yang optimal.
5. Deep Learning: Jaringan Saraf Tiruan dan Pembelajaran Mendalam
Deep Learning (DL) adalah cabang ML yang menggunakan jaringan saraf tiruan (artificial neural networks) dengan banyak lapisan (deep neural networks) untuk menganalisis data yang kompleks. Jaringan saraf tiruan terinspirasi oleh struktur dan fungsi otak manusia. Setiap lapisan dalam jaringan saraf tiruan memproses data dan mengekstrak fitur-fitur yang lebih kompleks.
Cara kerja AI dan Machine Learning dalam Deep Learning sangat bergantung pada kemampuan jaringan saraf tiruan untuk mempelajari representasi data yang hierarkis. Artinya, lapisan-lapisan awal dalam jaringan saraf tiruan mempelajari fitur-fitur dasar seperti tepi dan sudut, sedangkan lapisan-lapisan yang lebih dalam mempelajari fitur-fitur yang lebih kompleks seperti objek dan konsep.
Beberapa arsitektur jaringan saraf tiruan yang populer meliputi:
- Convolutional Neural Networks (CNNs): Sangat efektif dalam memproses gambar dan video. CNNs menggunakan lapisan konvolusi untuk mengekstrak fitur-fitur penting dari gambar.
- Recurrent Neural Networks (RNNs): Sangat efektif dalam memproses data sekuensial seperti teks dan ucapan. RNNs menggunakan lapisan rekuren untuk mengingat informasi dari langkah-langkah sebelumnya dalam sekuens.
- Transformers: Arsitektur jaringan saraf tiruan yang relatif baru dan sangat efektif dalam memproses bahasa alami. Transformers menggunakan mekanisme perhatian (attention mechanism) untuk fokus pada bagian-bagian penting dari input.
Deep Learning telah mencapai kesuksesan yang luar biasa dalam berbagai aplikasi, termasuk:
- Pengenalan Wajah (Face Recognition)
- Pengenalan Ucapan (Speech Recognition)
- Terjemahan Bahasa (Language Translation)
- Pengolahan Bahasa Alami (Natural Language Processing)
- Mobil Swakemudi (Self-Driving Cars)
6. Tantangan dan Pertimbangan Etika dalam AI dan Machine Learning
Meskipun AI dan ML menawarkan potensi yang luar biasa, ada juga tantangan dan pertimbangan etika yang perlu diperhatikan. Beberapa tantangan utama meliputi:
- Bias dalam Data: Jika data pelatihan mengandung bias, model ML yang dilatih menggunakan data tersebut juga akan bias. Hal ini dapat menyebabkan diskriminasi dan ketidakadilan.
- Overfitting dan Underfitting: Overfitting terjadi ketika model terlalu kompleks dan hanya bagus pada data pelatihan, tetapi tidak dapat menggeneralisasi dengan baik ke data baru. Underfitting terjadi ketika model terlalu sederhana dan tidak dapat menangkap pola-pola penting dalam data.
- Explainability dan Interpretability: Sulit untuk memahami cara kerja AI dan Machine Learning yang kompleks, terutama model Deep Learning. Hal ini menyulitkan untuk memvalidasi dan memperbaiki model, serta untuk menjelaskan mengapa model membuat keputusan tertentu.
- Privasi Data: Penggunaan data pribadi untuk melatih model ML dapat menimbulkan masalah privasi. Penting untuk memastikan bahwa data pribadi digunakan secara bertanggung jawab dan sesuai dengan peraturan yang berlaku.
- Dampak Sosial dan Ekonomi: Otomatisasi yang didorong oleh AI dan ML dapat menyebabkan hilangnya pekerjaan dan ketidaksetaraan ekonomi. Penting untuk mempertimbangkan dampak sosial dan ekonomi dari AI dan ML dan mengambil langkah-langkah untuk mengurangi dampak negatifnya.
Pertimbangan etika dalam AI dan ML meliputi:
- Keadilan: Memastikan bahwa model AI dan ML tidak bias dan tidak menyebabkan diskriminasi.
- Transparansi: Membuat model AI dan ML lebih mudah dipahami dan diinterpretasikan.
- Akuntabilitas: Menetapkan tanggung jawab atas keputusan yang dibuat oleh model AI dan ML.
- Privasi: Melindungi data pribadi yang digunakan untuk melatih model AI dan ML.
- Keamanan: Memastikan bahwa model AI dan ML tidak dapat disalahgunakan untuk tujuan jahat.
7. Contoh Aplikasi AI dan Machine Learning dalam Kehidupan Sehari-hari
Cara kerja AI dan Machine Learning telah diterapkan dalam berbagai aplikasi di kehidupan sehari-hari. Berikut beberapa contohnya:
- Sistem Rekomendasi: Netflix, Spotify, dan Amazon menggunakan AI dan ML untuk merekomendasikan film, musik, dan produk yang mungkin Anda sukai.
- Asisten Virtual: Siri, Google Assistant, dan Alexa menggunakan AI dan ML untuk memahami perintah suara Anda dan memberikan jawaban atau melakukan tindakan yang sesuai.
- Filter Spam: Gmail dan layanan email lainnya menggunakan AI dan ML untuk memfilter email spam dan melindungi Anda dari penipuan.
- Deteksi Fraud: Bank dan perusahaan kartu kredit menggunakan AI dan ML untuk mendeteksi transaksi yang mencurigakan dan mencegah penipuan.
- Mobil Swakemudi: Tesla dan perusahaan otomotif lainnya menggunakan AI dan ML untuk mengembangkan mobil swakemudi.
- Diagnosis Medis: AI dan ML digunakan untuk membantu dokter mendiagnosis penyakit dengan menganalisis gambar medis dan data pasien.
8. Masa Depan AI dan Machine Learning: Inovasi dan Tren Terkini
Masa depan AI dan ML sangat cerah. Inovasi dan tren terkini termasuk:
- Explainable AI (XAI): Fokus pada pengembangan model AI yang lebih mudah dipahami dan diinterpretasikan.
- Federated Learning: Melatih model AI pada data yang terdistribusi di berbagai perangkat atau server tanpa membagikan data mentah.
- Generative AI: Menggunakan AI untuk menghasilkan konten baru seperti gambar, teks, dan musik. Contohnya termasuk model seperti DALL-E 2 dan GPT-3.
- AI for Social Good: Menggunakan AI untuk memecahkan masalah sosial dan lingkungan seperti perubahan iklim, kemiskinan, dan kesehatan.
9. Sumber Daya untuk Belajar AI dan Machine Learning
Jika Anda tertarik untuk mempelajari lebih lanjut tentang AI dan ML, ada banyak sumber daya yang tersedia:
- Kursus Online: Coursera, edX, Udacity, dan DataCamp menawarkan berbagai kursus tentang AI dan ML.
- Buku: Ada banyak buku bagus tentang AI dan ML, baik untuk pemula maupun untuk ahli.
- Blog dan Artikel: Banyak blog dan situs web yang membahas topik-topik terkait AI dan ML.
- Komunitas Online: Bergabunglah dengan komunitas online seperti Stack Overflow dan Reddit untuk bertanya dan berbagi pengetahuan dengan orang lain.
- Framework dan Library: Gunakan framework dan library seperti TensorFlow, PyTorch, dan scikit-learn untuk membangun model AI dan ML.
10. Kesimpulan: AI dan Machine Learning Mengubah Dunia
Cara kerja AI dan Machine Learning mungkin terdengar kompleks, tetapi dengan pemahaman yang baik tentang konsep dasar dan algoritma yang digunakan, Anda dapat mulai menjelajahi dunia AI dan ML yang menarik. AI dan ML memiliki potensi untuk mengubah dunia kita menjadi lebih baik, tetapi penting untuk mempertimbangkan tantangan dan pertimbangan etika yang terkait dengan teknologi ini. Dengan pendekatan yang bertanggung jawab dan inovatif, kita dapat memanfaatkan kekuatan AI dan ML untuk memecahkan masalah-masalah kompleks dan meningkatkan kualitas hidup kita. Jadi, tunggu apa lagi? Mari belajar dan berkontribusi dalam perkembangan AI dan ML!
Referensi:
Semoga artikel ini bermanfaat!









{kind=link}